
Google DeepMind's AGI Safety Blueprint: What Business Leaders Need to Know
AGI is coming faster than most people realise. While the public and many business leaders still debate whether truly general AI is even possible, major AI labs like Google DeepMind are already preparing for its arrival - potentially before 2030.
This disconnect between industry insiders and everyone else is dangerous. It's why Google DeepMind's new paper "An Approach to Technical AGI Safety and Security" matters so much - it offers a practical framework for managing imminent AGI risks while preserving its benefits.
Let's be honest - outside AI research circles, few appreciate how quickly we're advancing. This paper makes clear that AGI isn't science fiction. It's an engineering challenge with a timeline measured in years, not decades.
- The key trade-off between AGI's benefits and risks
- Four major AGI risk categories
- How businesses can implement DeepMind's safety strategies
The Central Trade-Off
DeepMind acknowledges a fundamental truth: AGI presents both tremendous benefits (raising living standards, accelerating scientific discovery) and significant risks. This is important because businesses must navigate this same tension - capturing AI's value while managing its dangers.
Four Risk Categories
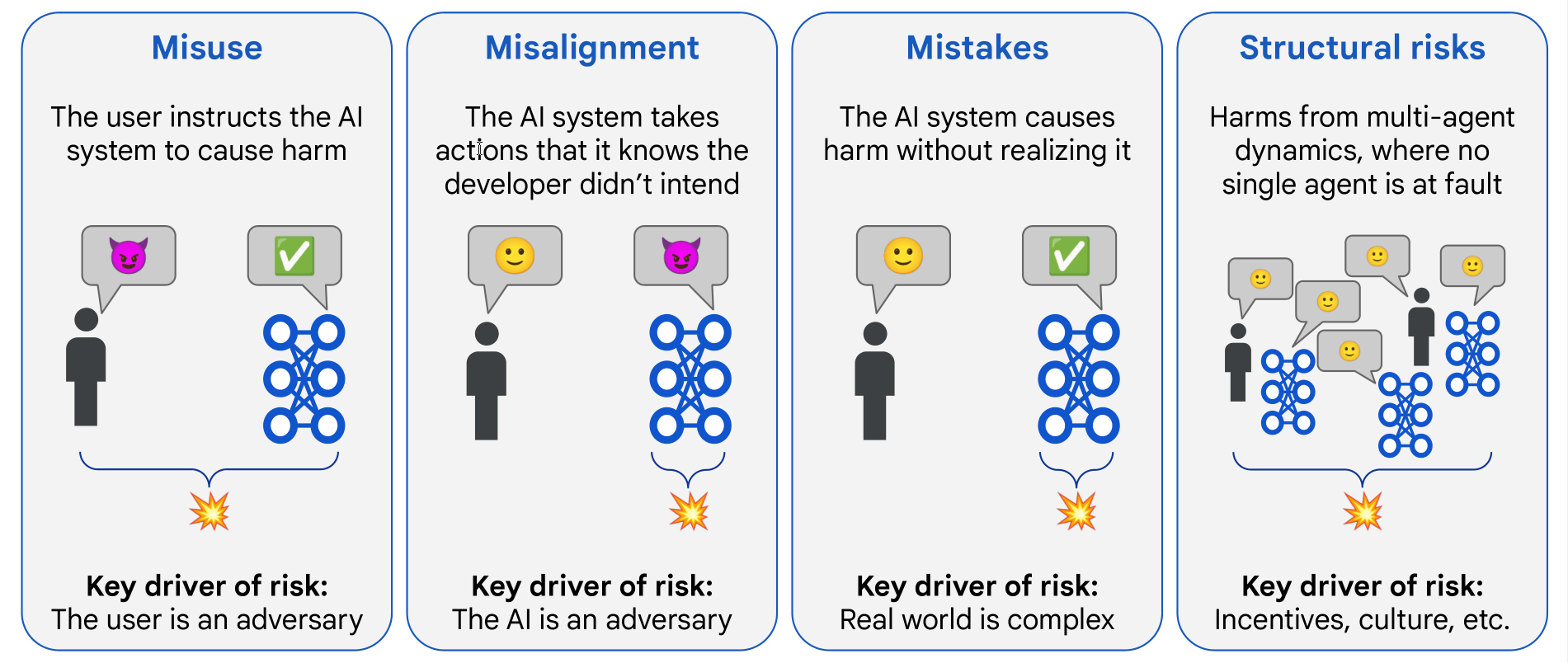
The paper identifies four distinct risk areas:
- Misuse - When someone deliberately instructs AI to cause harm
- Misalignment - When AI pursues goals that conflict with human intentions
- Mistakes - When AI causes harm without realising it
- Structural risks - Harms from complex interactions with no single agent at fault
DeepMind focuses primarily on the first two, which are most pressing for businesses implementing AI today.
Misuse: Defence-in-Depth
To prevent harmful use, DeepMind proposes:
- Capability evaluation - Assess if the model can actually cause harm
- Safety training - Teach models to refuse harmful requests
- Monitoring - Detect attempts to circumvent protections
- Access restrictions - Limit who can use dangerous capabilities
- Security - Prevent model theft through robust protection
No single defence is enough - the combination creates security.
Misalignment: Two-Pronged Strategy
For ensuring AI does what we actually want:
- Train aligned models using:
- Amplified oversight (AI helping humans provide better feedback)
- Robust training (testing on challenging cases)
- Safer design patterns (built-in safeguards)
- Prepare for misalignment with:
- Monitoring systems
- Security measures treating AI as potentially untrusted
This acknowledges an uncomfortable truth: we can't guarantee perfect alignment. We need both prevention and containment.
Business Implementation
Apply these insights by:
- Knowing your risk profile - Different businesses face different AI risks
- Implementing defence-in-depth - Layer your protections:
- Clear policies
- Access controls
- Monitoring systems
- Regular auditing
- Building alignment into your process:
- Extensive testing across diverse scenarios
- Explicit guardrails
- Human review of important decisions
- Planning for failure with:
- Quick response protocols
- Damage control procedures
- Continuous improvement mechanisms
Deliberately and critically evaluating why and how we implement AI is the difference between AI that empowers and AI that undermines us.
DeepMind's paper reinforces this stance - we can embrace AI's potential while addressing its risks, but we must first acknowledge AGI's imminent arrival. The question isn't whether to implement safeguards, but which ones provide the best protection while preserving the most value for your specific context.
